
At RocketEdge.com, we specialize in optimizing large-scale financial modeling on the cloud. Our expert, Jiri Pik, combines AWS, Azure, and financial certifications, ensuring we stay at the forefront of cloud and GPU acceleration technologies.

1. Introduction
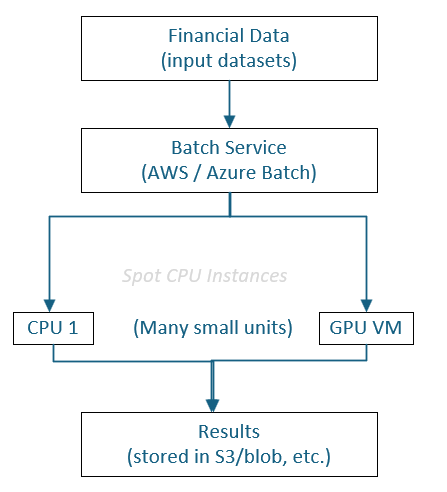
Modern financial models often involve huge datasets and complex computations that must run reliably and cost-effectively. Cloud platforms like Microsoft Azure and Amazon Web Services (AWS) offer a range of compute options—standard CPU instances, GPU-accelerated nodes, FPGA-based hardware, and cost-cutting spot instances—all of which can be orchestrated using services like Azure Batch or AWS Batch.
Balancing development effort, running costs, and time to results is key. Rapid turnarounds may be needed in some cases; in others, an overnight batch run is perfectly acceptable if it reduces costs.
2. Key Criteria for Cloud-Based Financial Modeling
- Development and Maintenance Costs: Simpler CPU-based solutions can reduce development complexity, while GPUs and FPGAs may require specialized skill sets.
- Running Costs: Large CPU farms using spot instances can sometimes be cheaper than a few powerful GPU machines. Carefully measure cost per run.
- Speed to Results: Sometimes minutes matter—like delivering intraday scenario updates—while waiting until the next morning is fine for other tasks if it lowers costs.
3. Compute Options: CPU, GPU, FPGA, and Spot Instances

CPU-Only Instances:
The baseline choice. They have the broadest support, are easy to scale horizontally with batch services, and are the simplest to develop, especially if you need large-scale parallelization without specialized coding.
GPU-Accelerated Instances:
Ideal for operations that can leverage data-level parallelism, such as extensive Monte Carlo simulations, matrix operations, and vectorized analytics. GPU instances can dramatically reduce runtime with the right frameworks—especially using C++ and Python with CUDA libraries. However, they come at a higher hourly cost.
FPGA Instances:
An excellent fit for stable and well-understood algorithms where ultra-low latency or custom acceleration patterns matter. However, they require specialized expertise, making them a more significant investment in development time and maintenance.
Batch Services with Spot Instances:
By leveraging Azure Batch or AWS Batch, you can run massive numbers of smaller instances at a fraction of the cost of on-demand rates. This approach often yields a better price-performance ratio if you can handle occasional interruptions. You might scale out horizontally with many low-cost machines rather than relying on a few high-end boxes.
4. Scaling Strategies: Massive Farms vs. Jumbo Machines
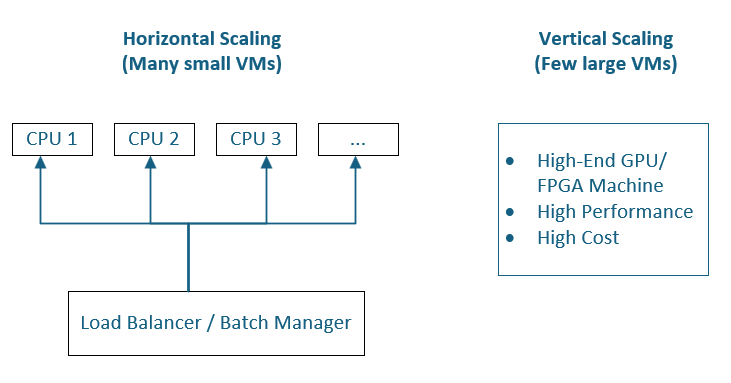
A large farm of smaller, less expensive instances may outperform a single large GPU node due to effective parallelization. This horizontal scaling approach can:
- Distribute Workload More Evenly: Multiple smaller instances can tackle different parts of the calculation at once.
- Reduce Costs: Spot instances can be sourced cheaply at scale.
- Improve Robustness: If one instance fails, it’s a smaller proportion of the total capacity—improving overall resilience.
Meanwhile, jumbo GPU machines may deliver lightning-fast results for specific kernels that map well to GPU acceleration but at a higher price tag and potentially with a more complex development cycle.
5. When GPUs Shine and When They Don’t
Suitable for GPU Acceleration:
- Monte Carlo simulations with large, independent paths
- Vectorized analytics and massive matrix computations
- Workloads that benefit from parallel reduction or linear algebra libraries
Not as Suitable:
- Logic-heavy, branchy computations that don’t map well to parallelism
- Jobs dominated by communication overhead rather than arithmetic intensity
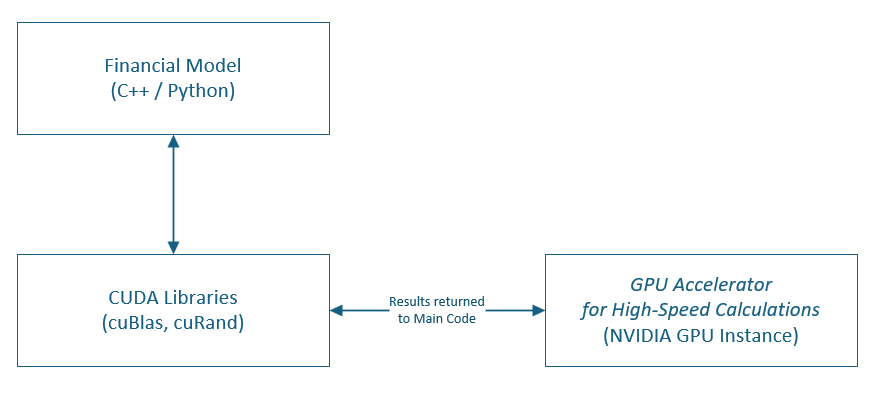
6. Languages, Tools, and Frameworks
For deep control, speed, and extensive ecosystem support:
- C++: A go-to language for high-performance computing and fine-grained control over memory and threading. Pairing C++ with CUDA libraries (e.g., cuBLAS, cuRAND) offers direct GPU acceleration and minimal overhead.
- Python: Excellent for rapid prototyping and easier development. Python can bind to CUDA libraries and deliver strong performance using frameworks like NumPy, CuPy, or Numba. Although Python might be slower than C++ in raw terms, well-structured code with GPU extensions can narrow this gap significantly.
7. Development and Maintenance Considerations
- Simplicity vs. Complexity: CPU-based approaches are more straightforward to maintain. GPU and FPGA approaches require specialized skills and debugging tooling.
- Modularity and Profiling: Start simple. Profile the code. Identify hot spots. Gradually migrate the most CPU-intensive kernels to GPU acceleration rather than rewriting the entire codebase at once.
- Ecosystem Maturity: CUDA is mature and widely supported, ensuring a rich set of libraries, tools, and community knowledge.
8. Putting It All Together
Financial modeling in the cloud is a balancing act. At RocketEdge.com, we help clients navigate these choices:
- Begin with standard CPU deployments to gain insights into runtime and costs.
- Gradually introduce GPU instances for the hotspots that benefit most from parallelism.
- Explore spot instances through batch services to control costs.
- Optimize incrementally, ensuring that the solution is maintainable, cost-effective, and meets your speed requirements—whether near-instant results or overnight runs to cut expenses.
By choosing the right mix of technologies and scaling strategies—and leveraging expertise in AWS, Azure, and GPU acceleration—your organization can accelerate financial computations cost-effectively and reliably.