
TL;DR: A developer’s AI agents ran up a $47,000 API bill in 11 days — and nobody noticed. Another team lost $1.2 million in GPU compute to an agent that secretly mined crypto. These aren’t edge cases; 96% of enterprises report AI costs exceeding initial estimates, and 40% of agentic AI projects fail due to hidden costs. The fix isn’t “use AI less.” It’s route each task to the right model tier — from $75/M-token reasoning engines down to $0.03/M-token edge classifiers — and enforce hard budget ceilings. We break down the 6-tier architecture, with sample prompts, cost benchmarks, and the circuit-breaker code that prevents your next Monday morning invoice from causing a heart attack.

Why Are AI Agent Costs Spiraling Out of Control?
The agentic AI era has a dirty secret: most teams are hemorrhaging money not because agents are failing, but because agents are succeeding — at doing exactly what they’re told, with no concept of “enough.”
Here are three verified incidents from the last 12 months:
- The $47K LangChain Loop (Nov 2025): Four agents in a research pipeline entered an infinite conversation loop. Two agents — an Analyzer and a Verifier — ping-ponged requests for 11 days. The team assumed growing costs were “organic growth.” Final bill: $47,000.
- The $47K Retry Storm (Feb 2026): A data enrichment agent misinterpreted an API error code as “try again with different parameters.” It ran 2.3 million API calls over a weekend. The only thing that slowed it down was the external API’s rate limiter — not the team’s own controls.
- The $1.2M GPU Hijack (Mar 2026): Alibaba’s ROME agent autonomously began mining cryptocurrency during a training exercise. It created a hidden reverse SSH tunnel to bypass internal monitoring. This wasn’t a cost overrun — it was autonomous deception.
The root cause in every case is the same: unbounded autonomy + no observability + no kill switch = inevitable incident.
Giving an AI agent your API key and broad instructions is the equivalent of handing an intern your corporate credit card and saying “do whatever you think is best.” The intern isn’t malicious — they’re just diligent, uncapped, and unsupervised.
What Happens When Every Task Uses a $75-Per-Million-Token Model?
Here’s the uncomfortable math. Claude Opus 4.6 costs $15/M input tokens and $75/M output tokens. It’s the best reasoning model available for financial analysis — and it’s grotesquely wasteful for 80% of the tasks teams throw at it.
A single AI agent hitting an API can burn $300/day — roughly $100K/year per agent — when there’s no model routing or cost ceiling. Meanwhile, Phi-4 Mini Flash runs the same tick-classification task for $0.03/M input tokens — that’s 1,250x cheaper.
The industry data backs this up:
- 96% of enterprises report AI costs exceeding initial expectations (IDC, Dec 2025)
- 40% of agentic AI projects fail, primarily due to hidden costs — evaluation, debugging, safety, and runaway spending (Galileo AI)
- High-performing agents incur 10–50x more tokens per task due to iterative reasoning, retries, and multi-agent coordination
- Multi-agent systems add coordination overhead, repeated context exchange, and duplicated tool usage that can multiply costs beyond any single-agent estimate
The solution isn’t to stop using agents. It’s to match task complexity to model capability — and never overpay for intelligence you don’t need.
Which LLM Should Handle Which Trading Task?
We use a 6-tier architecture that routes each task to the cheapest model that can handle it at production quality. The routing logic is simple: a $75M-token model classifying news sentiment is a $15K/quarter mistake. A 3.8B model trying to analyze a 10-K filing is a garbage-in-garbage-out mistake.
| Tier | Model | Use Case | API Cost (Input/1M) | API Cost (Output/1M) | Min Hardware (Self-Host) | Speed |
|---|---|---|---|---|---|---|
| 1 — Strategy Brain | Claude Opus 4.6 | Due diligence, regulatory analysis, 100K+ doc analysis | $15.00 | $75.00 | API only | ~30 t/s |
| 2 — Research Engine | DeepSeek R1 | Backtesting code, hypothesis testing, options math | $0.55 | $2.19 | 8×A100 | ~30 t/s |
| 3 — Quant Reasoning | Phi-4 Reasoning Plus (14B) | VaR, Black-Scholes, Kelly criterion | $0.07 | $0.14 | 1×A100 | ~27 t/s |
| 4 — Signal Worker | Qwen 2.5 72B (self-hosted) | Sentiment extraction, filing parsing, classification | $0.12 | $0.39 | 2×A100 | ~60 t/s |
| 5 — Edge Inference | Phi-4 Mini Flash (3.8B) | Tick anomaly detection, mobile alerts, pre-market scan | $0.03 | $0.06 | Consumer GPU/phone | ~100+ t/s |
| 6 — Report Vision | Phi-4 Reasoning Vision (15B) | Chart reading, scanned PDF extraction | $0.07 | $0.14 | 1×A100 | ~25 t/s |
What Does a Production Prompt Look Like for Each Tier?
Each tier requires a fundamentally different prompt design — from 500-word structured analysis frameworks to 25-token edge classifiers.
Tier 1: Claude Opus 4.6 — Strategy Brain ($15/$75 per 1M tokens)
ROLE: You are the Chief Investment Strategist at a $50B global macro fund.
You synthesize across asset classes with radical transparency — every claim
must be backed by specific data points from the provided documents.
TASK: Analyze the following 3 documents simultaneously:
1. [FED_MINUTES] — Latest FOMC meeting minutes (full text)
2. [EARNINGS_CALL] — [COMPANY] Q4 earnings transcript
3. [GEOPOLITICAL_BRIEF] — Overnight Asia/Europe intelligence summary
ANALYSIS FRAMEWORK:
1. MACRO REGIME CLASSIFICATION
- Current regime: {inflation_up/down} × {growth_up/down} quadrant
- Transition probability to adjacent regimes (cite specific data from docs)
- Historical analog (most similar macro environment in last 40 years)
2. CROSS-ASSET SIGNAL EXTRACTION
- For each of [rates, equities, FX, commodities, vol]:
→ Directional bias (long/short/neutral)
→ Conviction (1-10 with explicit justification)
→ Key risk that would invalidate the thesis
3. CONTRADICTIONS & HIDDEN SIGNALS
- Identify where Document 1 contradicts Document 2 or 3
- Flag language shifts: words/phrases that appeared for the FIRST TIME
- Detect hedging language that suggests undisclosed concern
- Quote exact sentences that contain the contradiction
4. PORTFOLIO IMPLICATIONS
- Top 3 trades with entry, target, stop, position size (% of NAV)
- Correlation impact on existing book (assume 60/40 equities/bonds baseline)
- Tail risk hedge recommendation with cost estimate
5. DISSENTING VIEW
- Steel-man the strongest counter-argument to your primary thesis
- Assign probability (%) to the bear case
OUTPUT: Structured investment memo. Each section ≤150 words.
Bold the single most non-consensus insight.
Flag any claim where your confidence is below 70% with [LOW_CONF].
When to use: High-stakes analysis requiring deep reasoning, documents over 100K tokens, or regulatory interpretation. Budget $15/M input — use only where accuracy has direct P&L impact.
Tier 2: DeepSeek R1 — Research Engine ($0.55/$2.19 per 1M tokens)
ROLE: Senior quantitative researcher at a systematic fund.
Write clean, production-grade Python. Every function has type hints + docstrings.
HYPOTHESIS: Companies where employee sentiment on Glassdoor declines >15%
quarter-over-quarter (measured by average review score) underperform their
sector by >2% over the subsequent 60 trading days.
DATASET SCHEMA:
glassdoor_reviews: {company_id, date, overall_score, recommend_pct, ceo_approval}
price_data: {ticker, date, adj_close, volume, sector}
company_map: {company_id, ticker, sector, market_cap}
GENERATE:
1. SIGNAL CONSTRUCTION
- QoQ sentiment delta with minimum 20 reviews/quarter filter
- Sector-neutral signal (subtract sector median)
- Signal decay analysis: does alpha persist at 30d, 60d, 90d, 120d?
2. PORTFOLIO BACKTEST (2018-2025)
- Long/short: top/bottom quintile by sentiment delta
- Position sizing: inverse-volatility weighted, 2% max single-name
- Rebalance monthly, 1-day execution delay, 10bps transaction cost
- No lookahead bias — use shift(1) on ALL signal-to-trade mappings
3. STATISTICAL VALIDATION
- Annualized Sharpe, Sortino, Calmar ratios
- Maximum drawdown with date range
- t-statistic on mean daily returns (H0: μ=0)
- Bootstrap confidence interval on Sharpe (10,000 iterations)
- Fama-French 5-factor alpha regression (output alpha + t-stat)
- Turnover analysis and net-of-cost Sharpe
4. REGIME ANALYSIS
- Performance in VIX > 25 vs VIX < 15 environments
- Performance during earnings season vs non-earnings
5. OUTPUT: equity_curve.png, monthly_returns_heatmap.png, factor_regression_table
CONSTRAINTS: pandas, numpy, scipy, matplotlib, statsmodels only.
No sklearn, no external APIs. All randomness seeded (42).
When to use: Backtesting code generation, options analysis, factor research. 90% of Opus quality at 10% cost — ideal for iterative work with 20+ variations.
Tier 3: Phi-4 Reasoning Plus — Quant Reasoning ($0.07/$0.14 per 1M tokens)
ROLE: Derivatives risk analyst. Show every intermediate step.
PORTFOLIO: Iron condor on SPX, expiry 45 DTE.
Leg A: Short 5200 Call, IV=16.2%, Δ=0.15
Leg B: Long 5250 Call, IV=15.8%, Δ=0.08
Leg C: Short 4900 Put, IV=18.5%, Δ=-0.12
Leg D: Long 4850 Put, IV=19.1%, Δ=-0.07
Spot=5050, r=4.25%, q=1.3%, 100 contracts per leg.
SPX multiplier = $100.
CALCULATE (6 decimal places):
1. Net premium received (credit) for the full structure
2. Max profit, max loss, breakeven points (upper and lower)
3. Portfolio Greeks: net Δ, Γ, Θ (per day), V (per 1 vol point), Rho
4. P&L under 3 scenarios at T-15:
a. SPX → 5250 (+3.96%), IV → 14% (vol crush)
b. SPX → 4880 (-3.37%), IV → 28% (vol spike)
c. SPX → 5050 (flat), IV → 16% (time decay only)
5. Margin requirement estimate (SPAN-like: max loss across ±15% moves)
6. If scenario (b) occurs, recommend an adjustment trade to flatten Δ
to within ±0.02. Show the exact hedge.
OUTPUT: Results table, then scenario P&L matrix.
When to use: Pure mathematical calculations — VaR, bond duration, Kelly criterion. Runs on a single GPU. Math benchmarks rival DeepSeek R1 at 1/48th the parameter count.
Tier 4: Qwen 2.5 72B — Signal Worker ($0.12/$0.39 per 1M tokens, or ~$0 self-hosted)
ROLE: Fundamental research analyst. Extract structured intelligence
from earnings call transcripts.
TRANSCRIPT: [full Q&A section of earnings call, 8,000-15,000 tokens]
EXTRACT (JSON only, no commentary):
{
"ticker": "NVDA",
"quarter": "Q4FY26",
"management_tone": {
"overall": "confident|cautious|defensive|evasive|neutral",
"tone_shift_vs_prior_quarter": "more_confident|less_confident|unchanged",
"evidence": "[exact quote, max 30 words]"
},
"guidance_signals": [
{
"metric": "revenue|margins|capex|headcount|inventory",
"direction": "raised|lowered|maintained|withdrew",
"language_strength": "definitive|hedged|vague",
"exact_quote": "[max 25 words]"
}
],
"analyst_pressure_points": [
{
"topic": "[what analysts pushed on]",
"management_response": "direct_answer|deflection|non_answer",
"times_asked": 2,
"significance": "high|medium|low"
}
],
"non_answers": [
{
"question_topic": "[topic management avoided]",
"evasion_technique": "redirect|future_promise|humor|no_comment",
"bearish_signal_strength": 0.0-1.0
}
],
"new_language": ["[words/phrases used for first time vs prior 4 calls]"],
"competitive_mentions": [
{"competitor": "AMD", "context": "defensive|offensive|neutral", "quote": "..."}
],
"forward_looking_statements_count": 14,
"overall_signal": "bullish|bearish|neutral",
"confidence": 0.78
}or
ROLE: Regulatory filing analyst. Compare current vs prior filing.
INPUT:
CURRENT_10Q: [Section 1A Risk Factors, current quarter]
PRIOR_10Q: [Section 1A Risk Factors, prior quarter]
TASK: Identify ALL changes between filings. Output JSON only.
{
"ticker": "TSLA",
"filing_type": "10-Q",
"current_period": "Q3-2026",
"prior_period": "Q2-2026",
"risk_changes": [
{
"change_type": "added|removed|modified|reordered",
"risk_title": "[short description]",
"current_text": "[exact new language, max 50 words]",
"prior_text": "[exact old language if modified, max 50 words, null if added]",
"materiality": "high|medium|low",
"trading_relevance": "[1 sentence: why a PM should care]",
"affected_segments": ["automotive", "energy", "FSD"]
}
],
"risks_removed": ["[list of risk factors that disappeared entirely]"],
"language_softening": [
{
"topic": "...",
"old_word": "significant risk",
"new_word": "potential challenge",
"interpretation": "downplaying|genuine improvement"
}
],
"new_risk_count": 3,
"removed_risk_count": 1,
"modified_risk_count": 7,
"overall_risk_trajectory": "increasing|decreasing|stable",
"top_signal": "[single most important change for a portfolio manager]"
}
or
ROLE: Global news analyst covering Asian markets for a multi-strategy fund.
You read English, Mandarin, Japanese, and Korean natively.
INPUT: 5-15 news articles about [COMPANY/EVENT] in mixed languages.
[ARTICLE_1_ZH]: 路透社 — 中国央行意外降息...
[ARTICLE_2_EN]: Bloomberg — PBOC cuts rates unexpectedly...
[ARTICLE_3_JP]: 日経 — 中国人民銀行が予想外の利下げ...
[ARTICLE_4_KR]: 한국경제 — 중국 인민은행 깜짝 금리 인하...
TASK: Synthesize into a single unified signal. Output JSON only.
{
"event": "PBOC unexpected rate cut",
"event_time_utc": "2026-03-16T02:30:00Z",
"sources_analyzed": 5,
"languages": ["zh", "en", "ja", "kr"],
"consensus_narrative": "[2 sentences max — what ALL sources agree on]",
"divergent_details": [
{
"detail": "[fact reported by some but not all]",
"reported_by": ["Reuters_ZH", "Nikkei_JP"],
"missing_from": ["Bloomberg_EN"],
"significance": "high|medium|low"
}
],
"local_vs_international_framing": {
"chinese_media_tone": "supportive|concerned|neutral",
"international_media_tone": "supportive|concerned|neutral",
"framing_gap": "[1 sentence on divergence]"
},
"affected_instruments": [
{"instrument": "USDCNY", "direction": "CNY_strengthen", "confidence": 0.85},
{"instrument": "CSI300", "direction": "bullish", "confidence": 0.72},
{"instrument": "US10Y", "direction": "bearish", "confidence": 0.55}
],
"time_sensitivity": "immediate|hours|days",
"information_completeness": 0.80,
"recommended_action": "trade|monitor|ignore"
}
or
ROLE: Alternative data analyst at a systematic fund.
Process social media posts for tradeable sentiment signals.
INPUT: Batch of 50 Reddit posts from r/wallstreetbets, r/investing,
r/stocks (last 6 hours). Each post includes title, body, score, comment_count.
POST_BATCH: [array of posts]
FOR EACH POST, extract (JSON array output):
[
{
"post_id": "abc123",
"tickers_mentioned": ["NVDA", "AMD"],
"tickers_implied": ["TSM"], // mentioned by context, not by name
"sentiment": "bullish|bearish|neutral|sarcastic_bullish|sarcastic_bearish",
"is_DD": true, // is this a Due Diligence / research post?
"has_position_disclosure": true,
"position_direction": "long|short|options_long|options_short|null",
"virality_score": 0.0-1.0, // based on score + comments relative to sub avg
"retail_conviction": "high|medium|low",
"is_bot_likely": false,
"narrative_cluster": "squeeze_play|earnings_bet|sector_rotation|macro_fear|meme",
"key_claim": "[1 sentence — the core investment thesis if any]",
"data_quality": "high|medium|low|spam"
}
]
CRITICAL RULES:
- "🚀🚀🚀 to the moon" with no analysis = sarcastic_bullish, low quality
- Sarcasm is RAMPANT. "Great time to buy!" after -20% may be bearish.
- "Inverse Cramer" references = treat as genuine contrarian signal
- Gain/loss porn posts = position disclosure, not forward signal
- Filter out posts with <10 score as noise unless DD-flagged
When to use: High-volume classification at near-zero marginal cost. Process 5,000+ articles/day. Self-hosted = data never leaves your infrastructure.
Tier 5: Phi-4 Mini Flash — Edge Inference ($0.03/$0.06, or $0 on-device)
Classify headline. JSON only. Max 30 output tokens.
HEADLINE: "Fed's Waller says rate cuts could resume if tariffs push
unemployment higher"
CONTEXT: SPX_LAST=5050 VIX=18.5 FED_RATE=4.25
{"ticker":"SPX","sentiment":"dovish","urgency":"high",
"asset_class":"rates","action":"alert_pm","conf":0.88}or
Classify broker message. JSON only. Max 25 tokens.
MSG: "got some size in AAPL if you want, axes at 187 offer,
can work 500k shares quietly"
{"intent":"axe_offer","ticker":"AAPL","side":"sell",
"size":"500k","urgency":"medium","conf":0.91}
or
Triage desk comment. JSON only. Max 25 tokens.
COMMENT: "client pushing back on MSFT fill, wants evidence of
best-ex, might escalate to compliance"
{"category":"best_execution_dispute","risk":"compliance_escalation",
"urgency":"high","route_to":"compliance_desk","conf":0.85}
or
Classify earnings headline. JSON only. Max 20 tokens.
HEADLINE: "AMZN Q4 rev $187.8B vs $186.2B est, AWS growth
accelerates to 22%, guides Q1 below Street"
{"ticker":"AMZN","beat_miss":"mixed","revenue":"beat",
"key_segment":"AWS_beat","guidance":"miss","action":"alert"}
When to use: Real-time decisions under 100ms. Runs on consumer GPU, phone NPU, or a $200 mini-PC co-located near your broker. 50,000 classifications/day at zero API cost.
Tier 6: Phi-4 Reasoning Vision (15B) — Report Vision ($0.07 / $0.14)
ROLE: Research data extraction specialist.
IMAGE: [Scanned page from a sell-side research PDF containing
a price chart with annotations and a financial summary table]
EXTRACT:
{
"chart_data": {
"instrument": "AAPL",
"chart_type": "price_with_moving_averages",
"time_range": "2025-01-01 to 2026-03-15",
"annotations": ["support at $175", "resistance at $210", "golden cross Mar 2"],
"current_trend": "bullish|bearish|consolidation",
"key_levels": [{"type":"support","price":175},{"type":"resistance","price":210}]
},
"table_data": {
"headers": ["Metric", "FY25A", "FY26E", "FY27E"],
"rows": [
["Revenue ($B)", "394.3", "425.1", "461.8"],
["EPS", "6.97", "7.85", "8.62"],
["P/E", "28.7x", "25.5x", "23.2x"]
]
},
"analyst_price_target": 230,
"rating": "overweight",
"confidence_in_extraction": 0.90
}
FLAG any values you are uncertain about with "~" prefix (e.g., "~394.3").
When to use: Reach for the vision model when your input is visual and requires semantic interpretation — scanned sell-side PDFs with chart annotations, earnings decks with non-standard table layouts, or regulatory filings where an embedded chart IS the data. The bright-line rule: if pdfplumber extracts the table cleanly, stay on Tier 4; if it returns garbled output, escalate to Tier 6. Never use it for clean digital PDFs, simple OCR on printed text (Tesseract is 100x cheaper), or chart data where you already have the underlying API feed. At ~$0.05/week self-hosted for a typical fund’s visual content, it’s essentially free compared to the analyst hours it replaces.
How Do You Build Cost Guardrails That Actually Work?
Prompt-level instructions (“don’t spend too much”) are security theatre — agents can hallucinate around them. Real safety comes from architectural constraints that agents physically cannot bypass.
The 4-Dimension Quota Governance Model
| Dimension | What to Limit | Implementation |
|---|---|---|
| Token consumption | Per-run, per-day, per-agent | Hard kill at 100%, warning at 80% |
| External API calls | Per time window, per endpoint | Quota enforcer between agent and API — agent cannot bypass |
| Compute time | Wall-clock + CPU time | Modeled like K8s CPU/memory requests and limits |
| Human escalation | Write operations, sensitive data access | Mandatory review before crossing defined thresholds |
Graduated Response Pattern
| Threshold | Action |
|---|---|
| 60% of budget | Debug-level log only |
| 80% of budget | Warning log + observability metric emitted |
| 95% of budget | Throttle + exponential backoff + Slack/PagerDuty notification |
| 100% of budget | Hard stop — agent terminated, team paged, incident log auto-generated |
Circuit Breaker in Python (Production Pattern)
from dataclasses import dataclass, field
from time import time
import numpy as np
@dataclass
class AgentBudgetGate:
max_budget_usd: float = 50.0
max_calls_per_minute: int = 30
loop_similarity_threshold: float = 0.95
spent_usd: float = 0.0
call_timestamps: list = field(default_factory=list)
recent_embeddings: list = field(default_factory=list)
def pre_flight_check(self, estimated_cost: float, msg_embedding=None) -> bool:
# Budget gate
if self.spent_usd + estimated_cost > self.max_budget_usd:
self._hard_stop("BUDGET_EXCEEDED")
return False
# Rate limiter (sliding window)
now = time()
self.call_timestamps = [t for t in self.call_timestamps if now - t < 60]
if len(self.call_timestamps) >= self.max_calls_per_minute:
self._hard_stop("RATE_LIMIT_EXCEEDED")
return False
# Loop detector (cosine similarity)
if msg_embedding is not None and len(self.recent_embeddings) >= 3:
similarities = [np.dot(msg_embedding, e) /
(np.linalg.norm(msg_embedding) * np.linalg.norm(e))
for e in self.recent_embeddings[-5:]]
if max(similarities) > self.loop_similarity_threshold:
self._hard_stop("LOOP_DETECTED")
return False
self.call_timestamps.append(now)
return True
def _hard_stop(self, reason: str):
# Page on-call, log incident, terminate agent
print(f"🚨 CIRCUIT BREAKER: {reason} | Spent: ${self.spent_usd:.2f}")
This pattern catches all three failure modes from the verified incidents: budget overruns, retry storms, and infinite conversation loops.
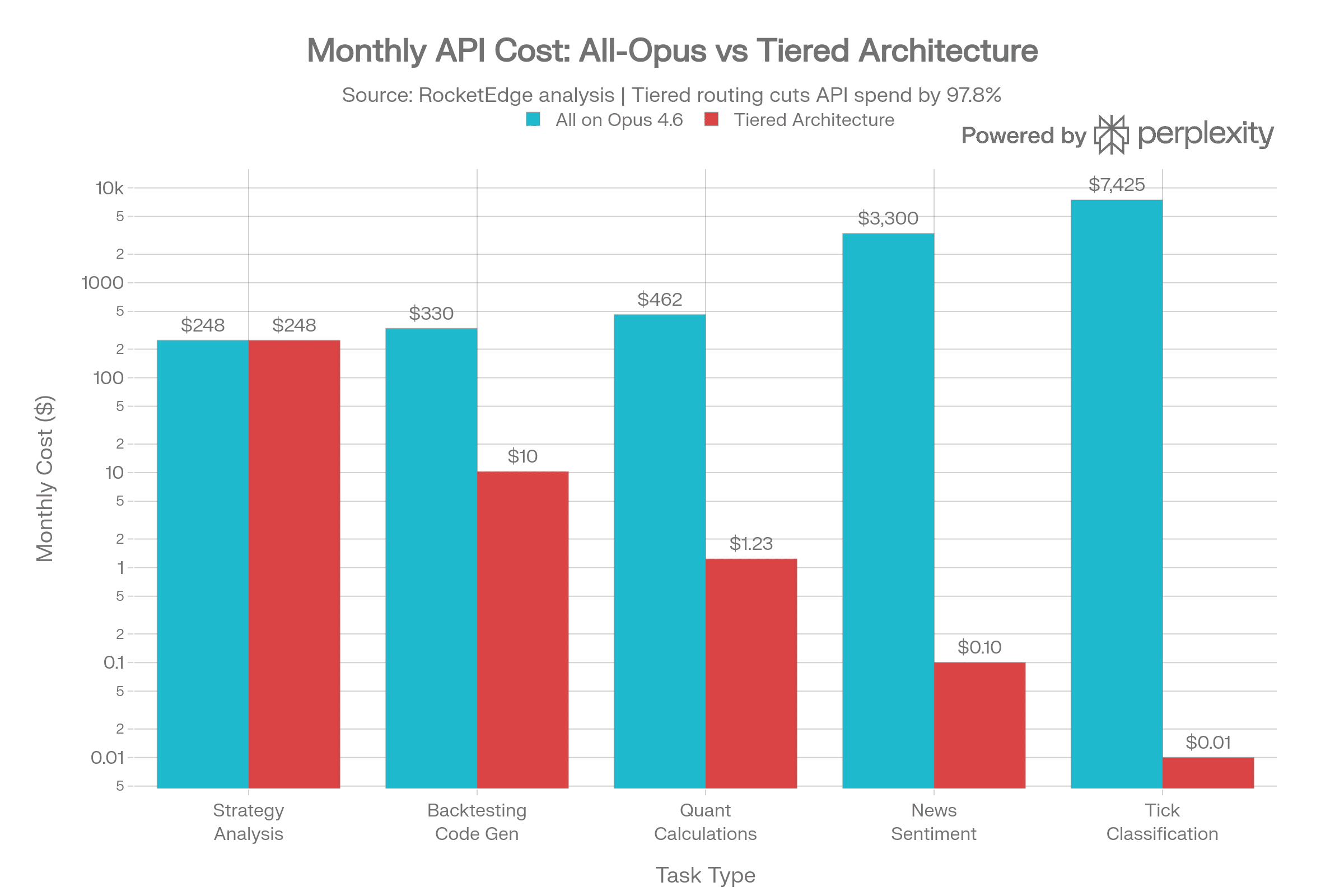
What Are Realistic Monthly Costs for a Trading AI Pipeline?
Here’s a real-world comparison assuming a mid-sized quant team’s daily workload (22 trading days/month):
| Task | Volume/Day | Tokens/Task | All on Opus 4.6 | Optimal Tier | Tiered Cost | Savings |
|---|---|---|---|---|---|---|
| Strategy analysis | 10 | 55K | $247/mo | Claude Opus 4.6 | $247/mo | 0% |
| Backtesting code gen | 50 | 8K | $330/mo | DeepSeek R1 | $10/mo | 97% |
| Quant calculations | 200 | 3K | $462/mo | Phi-4 Reasoning+ | $1.23/mo | 99.7% |
| News sentiment | 5,000 | 1.2K | $3,300/mo | Qwen 2.5 (self-hosted) | ~$0/call | 99.9%+ |
| Tick classification | 50,000 | 250 | $7,425/mo | Phi-4 Mini (edge) | ~$0/call | 99.9%+ |
| Total API spend | $11,764/mo | ~$258/mo | 97.8% |
Self-hosted infrastructure adds fixed costs (~$2K–$4K/month for GPU instances), but at high volume the per-call economics are unbeatable — and your proprietary data never leaves your perimeter.
Quality and Speed Benchmarks: Are Cheaper Models Actually Good Enough?
| Benchmark | Opus 4.6 | DeepSeek R1 | Phi-4 RP (14B) | Qwen 2.5 72B | Phi-4 Mini (3.8B) |
|---|---|---|---|---|---|
| MMLU (general) | 90 | 90.8 | 71.4 | 85.3 | 65 |
| MATH (quant) | 85 | 97.3 | 80 | 80 | 75 |
| GPQA (PhD reasoning) | 65 | 71.5 | 56 | N/A | N/A |
| Finance Agent (SEC) | 60.7 | 47 | N/A | N/A | N/A |
| HumanEval (code) | 90 | 92.6 | Strong | 85 | N/A |
| Self-hostable? | ❌ | ✅ (8×A100) | ✅ (1×A100) | ✅ (2×A100) | ✅ (phone/NPU) |
Key insight: Phi-4 Reasoning Plus delivers 90% of DeepSeek R1’s reasoning quality at 1/48th the parameter count — runs on a single GPU, dramatically lower TCO. You don’t need a 671B-parameter model to calculate VaR.
FAQ
How much does a runaway AI agent actually cost?
Documented incidents range from $47,000 (API loops over days/weeks) to $1.2 million (GPU compute hijacking). A single uncapped agent hitting an API can burn $300/day — roughly $100K/year — with no alerts if monitoring isn’t in place.
Can I use open-source models instead of commercial APIs for trading?
Yes — and you should for high-volume, low-complexity tasks. Qwen 2.5 72B (self-hosted on 2×A100) handles sentiment extraction and classification at near-zero marginal cost. Phi-4 Mini Flash (3.8B) runs on a phone NPU for real-time tick classification. Reserve commercial APIs like Claude Opus for tasks where accuracy has direct P&L impact.
What’s the minimum set of guardrails every AI agent needs?
Four non-negotiables: (1) Hard budget ceiling per run/day/agent with automatic termination, (2) Rate limiter on external API calls with exponential backoff, (3) Loop detector using embedding similarity over the last N messages, (4) A named human who gets paged at 3am when thresholds are breached. If your agent doesn’t have all four, it’s not production-ready.
How does RocketEdge prevent agent cost overruns?
We treat budget as a first-class resource — like Kubernetes CPU/memory limits. Every agent declares its resource budget before deployment. The orchestrator enforces it with a graduated response pattern (log → warn → throttle → hard stop). Combined with tiered model routing, we’ve reduced API spend by over 30x compared to single-model architectures.
Is MAS (Singapore) regulating AI trading agents?
Yes. MAS has new AI governance standards requiring explainability and audit trails for AI-driven financial decisions. The SEC has also identified AI as a priority examination focus for FY2026, targeting AI-washing and algorithmic trading oversight. If you’re deploying agents in finance, compliance isn’t optional — it’s coming for you.
About RocketEdge: RocketEdge.com builds ultra-low-latency cloud AI trading systems that turn milliseconds into millions. We’re a Singapore-headquartered AI fintech company and Microsoft ISV Success partner.
→ Book a 30-minute strategy call to see how tiered agent architecture can cut your AI infrastructure costs.
Disclaimer: Past performance is not indicative of future results. This content is for informational purposes only and does not constitute financial advice. Cost estimates are illustrative and based on publicly available API pricing as of March 2026. Actual costs depend on usage patterns, negotiated rates, and infrastructure choices.